개요
사이드 프로젝트 인생퍼즐 개발을 진행하면서, 이번에 몇몇 버그를 마주하게 되었다. 이번에 발생한 버그들은 배포된 앱이 정상적으로 동작하지 않도록 만든 케이스였다.
프리티어 만료로 인하여 AWS에 구성해둔 서버를 옮기게 되었는데, 이 때도 서버 이전 도중 문제가 발생하여 배포된 앱이 API를 호출하는 데에 문제가 발생해 앱 동작이 멈추었다.
이런 과정을 겪고나니, 장애가 발생했을 때 어떻게 대응하는 것이지 알아보고 사이드 프로젝트에 적용할 수 있는 것은 해보기로 했다.
장애란?
장애는 일시적으로나 영구적으로 시스템, 서비스, 또는 기능이 제대로 작동하지 않는 상황으로 기술적인 결함으로 하드웨어 또는 소프트웨어의 오류, 인프라, 네트워크, 보안 문제 등 다양한 요인에 의해 발생한다.
장애 대응 절차가 필요한 이유
장애를 잘 대처할수록 서비스를 이용하는 고객의 만족도 및 신뢰성을 얻을 수 있습니다. 이것은 조직의 손실 방지로 이어지게 됩니다.
장애 대응 절차
장애 대응은 5가지 절차로 이루어진다.
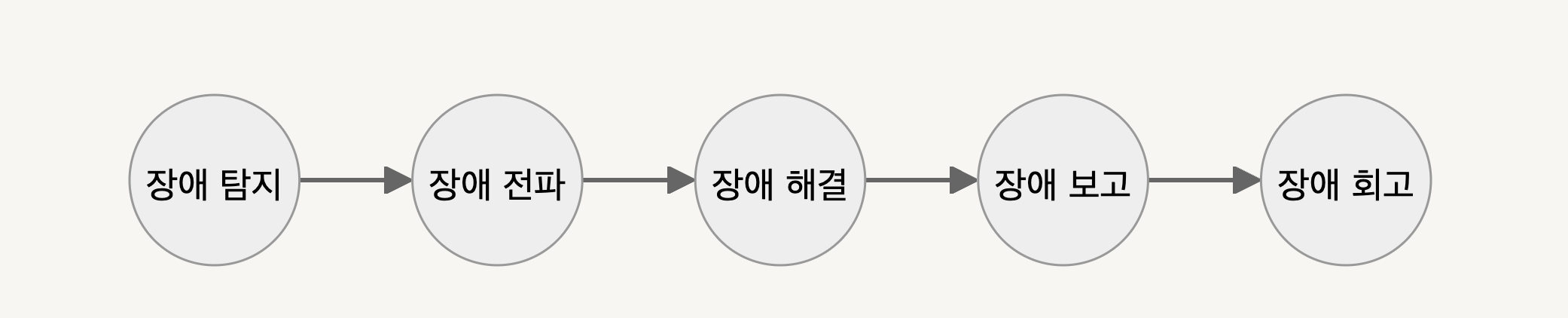
장애 탐지
고객의 CS문의를 통해 서비스에서 발생하는 장애를 확인할 수 있다. 하지만 이 경우 고객에게 서비스 사용하는 데에 불편함을 줄 수 있기 때문에 운영하는 쪽에서 미리 파악을 할 수 있으면 좋다. 모니터링 시스템을 구축하고 이를 통해 장애를 빠르게 탐지할 수 있다.
장애 전파
서비스 장애와 관련되어 있는 팀에게 빠른 전파를 해야 한다. 정보의 전달이 빠르게 이루어져야 CS팀은 고객에게 적절한 대응을 할 수 있으며, 개발팀은 서비스의 복구가 가능해진다.
장애 전파는 한 번으로 끝나는 것이 아닌, 장애가 해결이 될 때까지 주기적으로 정보를 공유해줘야 한다. 정보 공유를 통해 각 팀에서도 적절한 대응을 계속해 나갈 수 있기 때문이다.
장애 해결
개발팀은 원인 파악보다 빠른 복구를 우선시 해야하기 때문에 롤백, 서버 재기동, 장애 메뉴얼을 통한 수정 등 방법을 사용하여 서비스 장애를 해결해야 한다. 그리고 이를 혼자 해결하려고 하면 안됩니다. 이는 장애 해결을 더디게 할 수 있는 요소입니다. 함께 일하는 동료에게 공유를 한다면 다양한 인사이트를 통해서 빠른 장애 해결을 할 수 있습니다.
장애 보고
장애를 해결한 다음에는 이후에 발생할 수 있는 장애 예방 및 해결에 도움을 주기 위해 보고서를 작성해야 합니다. 보고서(지식)가 쌓이면 더 빠른 장애 해결을 할 수 있으며, 고객에게 서비스의 만족도를 앉겨줄 수 있습니다.
장애 보고서는 장애 등급, 장애 현상, 장애 영향 범위, 장애 원인, 장애 처리 타임라인별 행동, 장애 해결 방안 등 항목이 포함이 되어야 합니다. 정해진 규격은 없으며, 조직 내에서 협의를 하여 필요한 항목들을 정하면 됩니다.
장애 회고
장애 해결에서 빠른 복구를 우선시 했기 때문에 아직 정확한 원인 파악 및 개선이 이루어지지 않았습니다. 그래서 팀 내, 개발자 전체 회고를 통해서 장애 원인을 파악하고 발생하지 않도록 예방하는 방법에 대해 논의하고 결정합니다. 그리고 장애 대응하는 과정에서 부족함이 있었다면 개선 사항에 대해서도 이야기하고 발전시켜나가야 합니다.
'프로젝트' 카테고리의 다른 글
| IntelliJ Compound 기능으로 여러 프로젝트를 한 번에 실행시키기 (0) | 2024.05.12 |
|---|---|
| 기존 API 응답 형식 변경할 때 주의점 (0) | 2024.04.28 |
| AWS API 사용에 있어 요청 할당량 고려하기 (0) | 2024.03.17 |
| Java에서 AWS SDK를 사용할 때 발생하는 Warning & Error 로그 제거 (0) | 2024.03.03 |
| Redis I/O에서 생기는 동시성 문제 (0) | 2024.01.28 |
